Changes to memory ordering are made both by the compiler (at compile time) and by the processor (at run time), all in the name of making your code run faster.
Both CPU and compiler, cannot modify the behavior of a single-threaded program.
Hence memory reordering is not observed by the end user in single threaded programs, and multi threaded programs using synchronization primitives.
Memory reordering is observed only in case of a lock free program with shared memories.
Java’s volatile and C++’s atomic provided sequentially consistent data types (On the same CPU, Load and store on these data types happen in the order they are expressed in the program.)
Important to understand what sequential consistency is: the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. - Leslie Lamport
What the above statement means is, that, for each thread, operations need to happen in program order. A thread T1 with operations A1, B1 and C1 will have to execute these operations in that sequence. Across multiple processors, the sequence is undefined. Thread T2 with operations A2 and B2, can be scheduled in anyway with respect to thread T1 as long as A2 and B2 maintain their mutual order between themselves. Sequential consistency gaurantees Program Order.
In the image below, write from P1 and P2 may be scheduled in any order amongst themselves, but once an ordering has been decided, P3 and P4 should see them in the same order.
Processor Reordering
A processor is allowed to reorder instruction (memory interations), as long it never changes the execution of a single-threaded program.
Processor is allowed to delay the effect of a store past any load from a different location.
Assuming the above code is running parallely on 2 processors, depending on execution flow, the expectation would be either or both of rax and rbx to be one.
Since processor is allowed to reorder independent memory interations, there is a possibility that both rax and rbx are zero.
To prevent this, introduce a CPU barrier between the two instructions. Here, we’d like to prevent the effective reordering of a store followed by a load. In common barrier parlance, we need a StoreLoad barrier.
On x86/64, mfence instruction is a full memory barrier (not just a Store Load barrier).
On x86/64, any locked instruction, such as xchg, also acts as a full memory barrier.
In Linux kernel, smb_mb, smb_wmb, smb_rmb act as platform independent memory barrier, write memory barrier, and read memory barrier respectively.
Compiler reordering
The compiler has some freedom to sort the order of operations during compile time in the hope of optimization.
asm volatile("" ::: "memory"); can be used to prevent compiler reordering, though it still doesn’t eliminate processor reordering.
1
2
3
X=1;asmvolatile("":::"memory");r1=Y;
In the above example, without the memory fence, since X, Y, and r1 are indepedent memory areas, compiler can reorganize for r1 = Y to happen before X = 1, which could lead to undesired results [IF THE ARE SHARED MEMORY AREAS.]
The memory fence gaurantees that memory operations don’t cross that boundary. Things above and below it can be reordered among themselves but cannot be reordered in such a way that they cross the memory fence.
In C++11 atomic library standard, every non-relaxed atomic operation acts as a compiler barrier as well.
1
2
3
4
5
6
7
8
9
intValue;std::atomic<int>IsPublished(0);voidsendValue(intx){Value=x;// <-- reordering is prevented here!IsPublished.store(1,std::memory_order_release);}
Atomic operations.
No thread can observe the atomic operation half complete.
Aligned reads and writes of simple types are usually atomic.
C++11 has std::atomic<T>::fetch_add to perform atomic read-modify-write.
Compare-and-swap
Programmers perform compare-and-swap in a loop to repeatedly attempt a transaction. This pattern typically involves copying a shared variable to a local variable, performing some speculative work, and attempting to publish the changes using CAS
Aquire and Release semantics
Acquire semantics is a property that can only apply to operations that read from shared memory, whether they are read-modify-write operations or plain loads. The operation is then considered a read-acquire. Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that follows it in program order.
Release semantics is a property that can only apply to operations that write to shared memory, whether they are read-modify-write operations or plain stores. The operation is then considered a write-release. Release semantics prevent memory reordering of the write-release with any read or write operation that precedes it in program order.
Acquire semantics will use LoadLoad and LoadStore memory barriers.
Release semantics will use LoadStore and StoreStore memory barriers.
Acquire and Release semantics can be used to perform lock free programming by passing message around threads that are working cooperatively.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
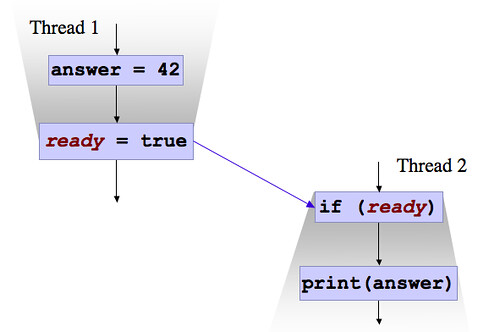
intPayload=0std::atomic<int>Signal=0;// Thread 1 produces data and sets the signal.// The signal cannot be reordered with data produced// else the other thread will receive bad datapayload=42;Signal.store(1,memory_order_release);// Thread 2 checks the signal and if the signal is set,// consumes the data from the shared payload. Checking the// signal cannot be reordered with using the payloadintsig=Signal.load(memory_order_acquire);if(sig)Use_data(payload);
The 2 acquire and release calls help the threads synchronize with each other.
Acquire semantic is analogous to acquiring a lock. Operation after it cannot be reordered to be before it.
Release semantic is analogous to releasing a lock. Operations before it cannot be reordered to be after it.